Predicting a house price using ML .NET
ML .Net is an opensource cross-platform machine learning framework intended for .NET developers. Python(with routines are written in C++) is generally used to develop many ML libraries, e.g. TensorFlow, and this can add extra steps and hurdles when you need to tightly integrate ML components on the .Net platform. ML .Net provides a great set of tools to let you integrate machine learning applications using .NET – you can find out more about ML .NET here
ML .NET lets you develop a range of ML systems
- Forecasting/Regression
- Issue Classification
- Predictive maintenance
- Image classification
- Sentiment Analysis
- Recommender Systems
- Clustering systems
ML .NET provides a developer-friendly API for machine learning, that supports the typical ML workflow:
- Loading different types of data (Test, IEnumerable
, Binary, Parquet, File Sets) - Transform Data Feature selection, normalization, changing the schema, category encoding, handling missing data
- Choosing an appropriate algorithm for your problem (Linear, Boosted trees, SVM, K-Means).
- Training (Training and evaluating models)
- Evaluating the model
- Deployment and Running(using the trained model)
A significant advantage of using the ML .NET framework is that it allows the user to quickly experiment with different learning algorithms, changing the set of features, sizes of training and test datasets to get the best results for their problem. Experimentation avoids a common issue where teams spend a lot of time collecting unnecessary data and produce models that do not perform well.
Learning Pipelines
ML .NET combines transforms for data preparation and model training into a single pipeline, these are then applied to training data and the input data used to make predictions in your model.
When discussing ML .NET, it is important to recognise to use of:
- Transformers - these convert and manipulate data and produce data as an output.
- Estimators - these take data and provide a transformer or a model, e.g. when training
- Prediction - this uses a single row of features and predicts a single row of results.
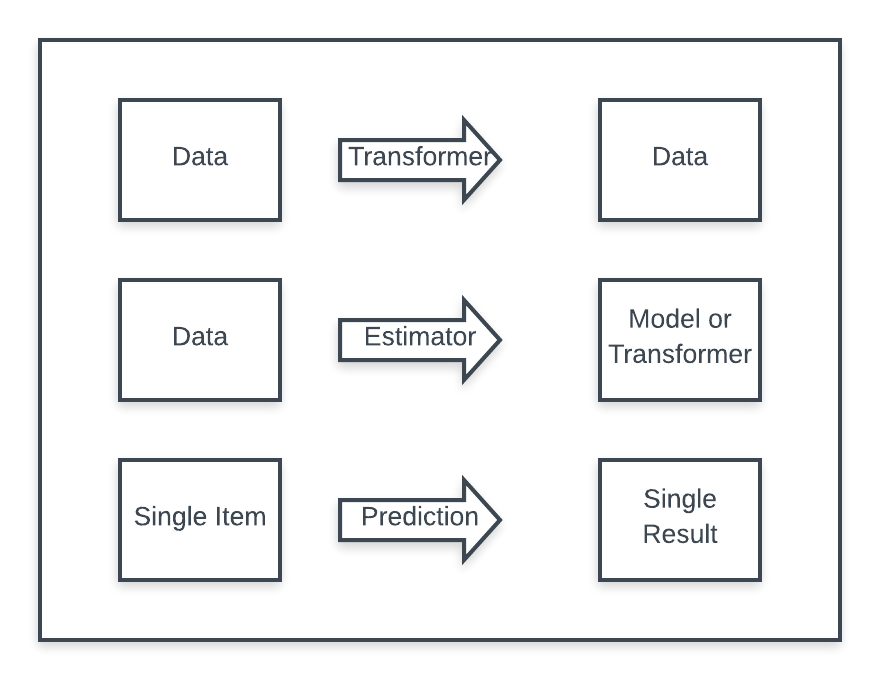
We will see how these come into play in the simple regression sample.
House price sample
To understand how the functionality fits into the typical workflow of data preparation, training the model and evaluating the fit using test data sets and using the model. I took a look at implementing a simple regression application to predict the sale price of a house given a simple set of features over about 800 home sales. In the sample, we are going to take a look at a supervised learning problem of Multivariate linear regression. A supervised learning task is used to predice the value of a label from a set of features. In this case, we want to use one or more features to predict the sale price(the label) of a house.
The focus was on getting a small sample up and running, that can then be used to experiment with the choice of feature and training algorithms. You can find the code for this article on GitHub here
We will train the model using a set of sales data to predict the sale price of a house given a set of features over about 800 home sales. While the sample data has a wide range of features, a key aspect of developing a useful system would be to understand the choice of features used affects the model.
Before you start
You can find a 10 minute tutorial that will take you through installing and pre requisits - or just use the following steps.
You will need to have Visual Studio 16.6 or later with the .NET Core installed you can get there here
To start building .NET apps you just need to download and install the .NET SDK.
Install the ML.Net Package by running the following in a command prompt
dotnet add package Microsoft.ML --version 0.10.0
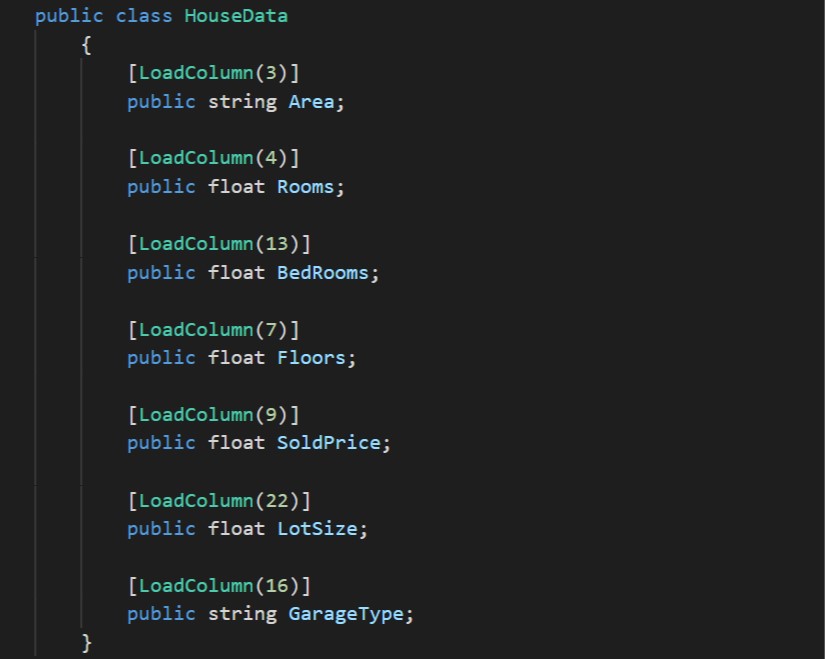
Data class
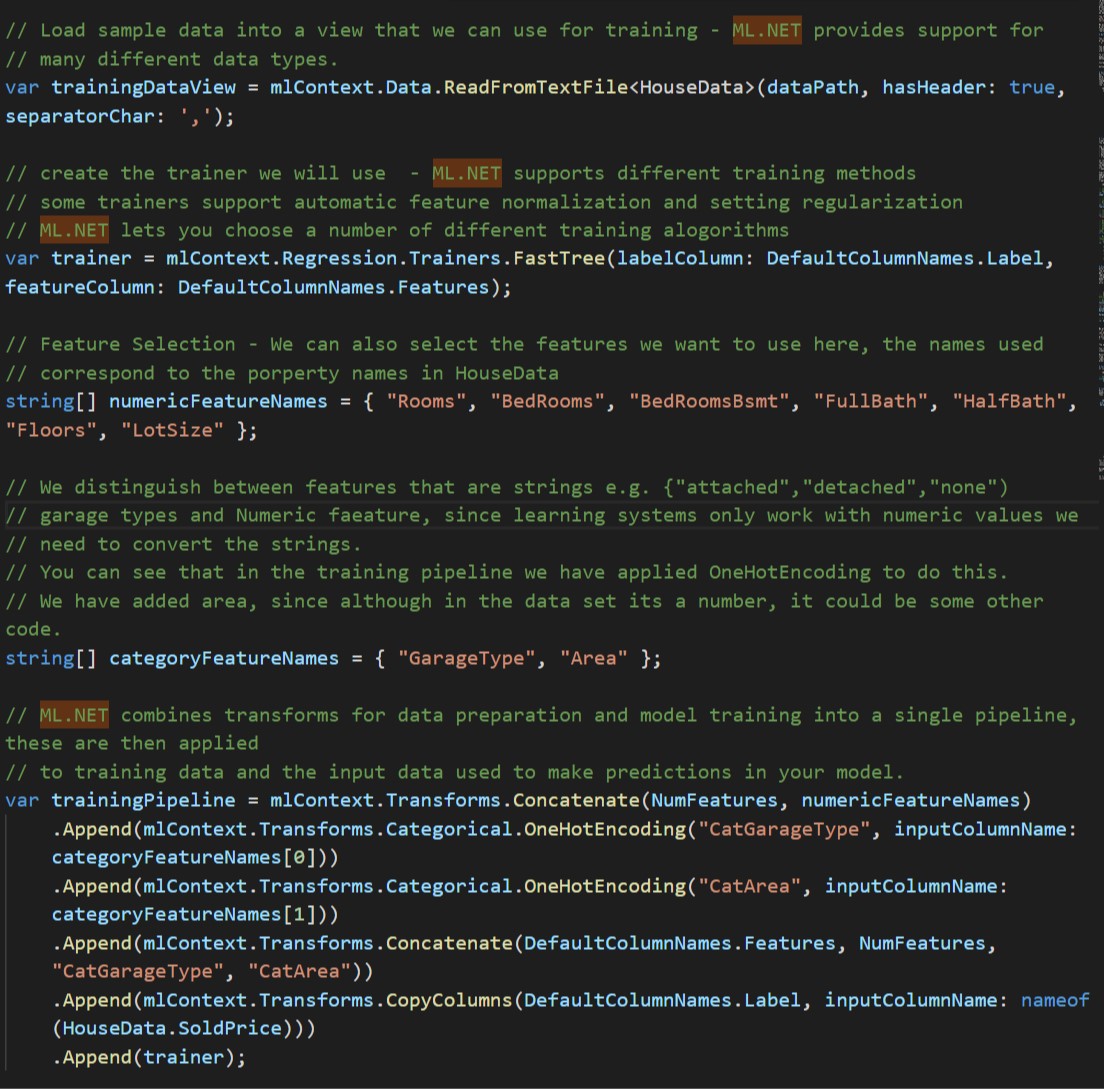
Our first job is to define a data class that we can use when loading our .csv file of house data. The important part to note is the [LoadColumn()] attributes; these allow us to associate the fields to different columns in the input. It gives us a simple way to adapt to changes in the data sets we can process. When a user wants to predict the price of a house they use the data class to give the features. Note, we do not need to use all the fields in the class when training the model.
Training and Saving the model
CreateHousePriceModelUsingPipeline(…) method does most of the interesting work in creating the model used to predict house prices.
The code snippet shows how you can:
- Read the data from a .csv file
- Choose the training algorithm
- Choose features to use when training
- Handle string features
- Create a pipeline to process the data and train the model
In these types of problem you will typically need to normalise the inbound data, consider the feature Rooms and BedRooms, the range of values of Rooms is usually larger then BedRooms, we normalise them to have the same influence on fit, and to speed up (depending on the trainer) the time to fitting. The trainer we using automatically normalises the features, though the framework provides tools to support normalizing if you need to do this yourself.
Similarly, depending on the number of features used (and if the model is overfitting) we apply Regularization to the trainer - this essentially keeps all the features but adds a weight to each of the features parameters to reduce the effect. In the sample, the trainer will handle regularisation; alternatively, you can make regularisation adjustments when creating the trainer.
Evaluation
After training we need to evaluate our model using test data, this will indicate the size of the error between the predicted result and the actual results. Reducing the error will be part of an iterative process on a relatively small set of data to determine the best mix of features. There are different approaches supported by ML .NET We use cross-validation to estimate the variance of the model quality from one run to another, it and also eliminates the need to extract a separate test set for evaluation. We display the quality metrics to evaluate and get the model’s accuracy metrics
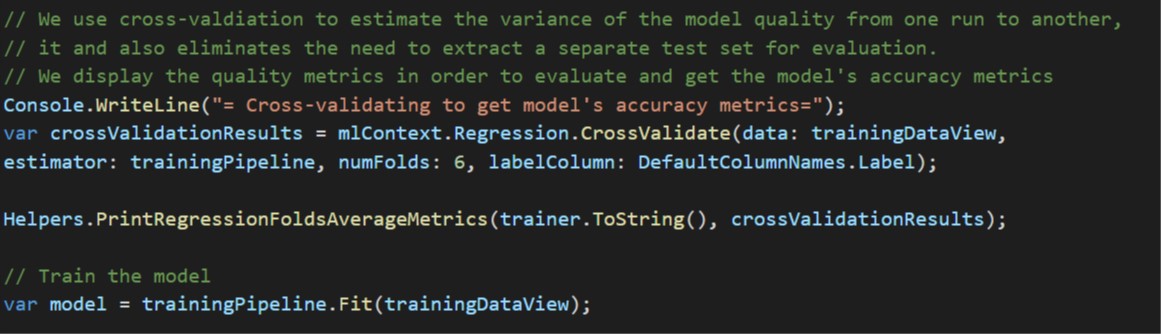
We will look at two metrics:
- L1 Loss - you need to minimise this, though if the input labels are not normalised, this can be quite high.
- R-squared - provides a measure of the goodness of fit, for linear regressions models will be between 0 -> 1, the closer to 1 the better.
The absolute loss is defined as L1 = (1/m) * sum( abs( yi - y’i))
You can find a desciption of the available metrics here
Running the code as is yeilds an R-Sqaured of 0.608, we will want to improve this. A first step would be to start to experiment with the feature selection, perhaps to start with a reduced list of features after we have a clearer understanding then consider getting a wider set of data.
Saving the model for later use
It is simple to store the model used to predict house prices
// Save the model for later comsumption from end-user apps
using (var file = File.OpenWrite(outputModelPath))
model.SaveTo(mlContext, file);
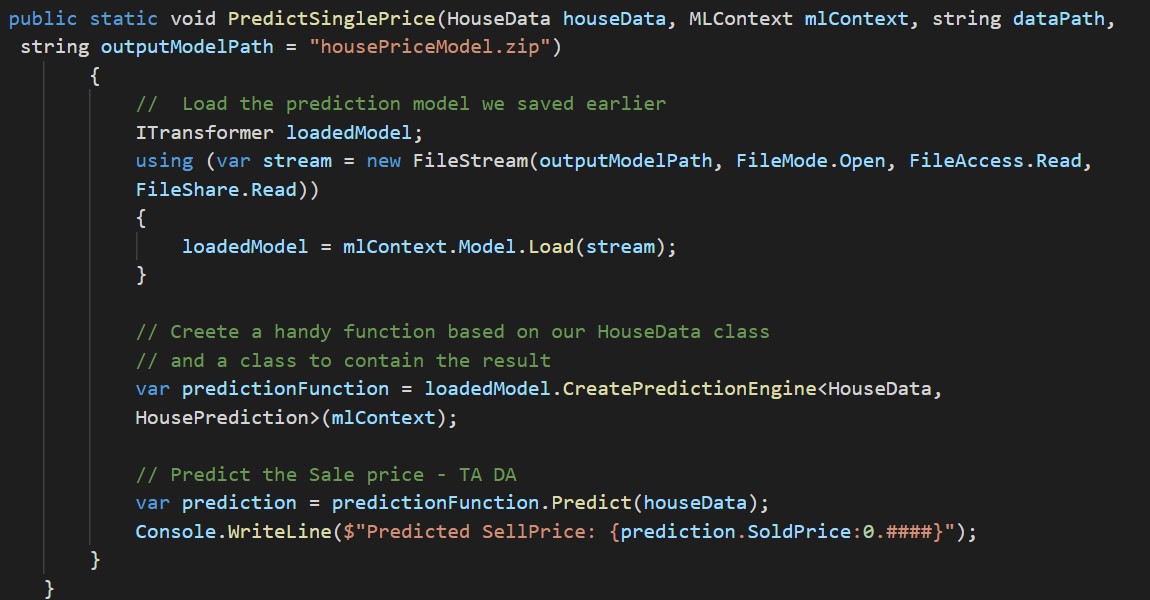
Load and predict house sale prices
Once you have tweaked the features and evaluate different training, you can then use the model to predict sales prices. I think this where the ML .NET framework shines because we can then use the cool tools in .Net to support different ways to use the model.
For this type of ML application, a typical use would be to create a simple REST service running in a docker container deployed to Windows Azure. A web app written in javascript consumes the service to let people quickly see what a house should sell for.
Using .Net Core we can run the backend on different hardware platforms, Visual Studio 2019, 2017 makes the creation, deployment, and management of a robust service quick and easy.